Es increíble poder extraer conclusiones de cantidades ingentes de datos. Y es que debido a estas conclusiones, a día de hoy nuestra información vale millones.
En esta ocasión voy a trabajar con R para extraer reglas de asociación de un dataset con centenares de miles de transacciones. En este caso las transacciones son filas donde un usuario escucha a un artista determinado un número X de veces. Esta notación es usada en el market basket análisis básicamente un estudio de tendencias y preferencias de mercado que trata de vender productos en base de los que un comprador ha adquirido.
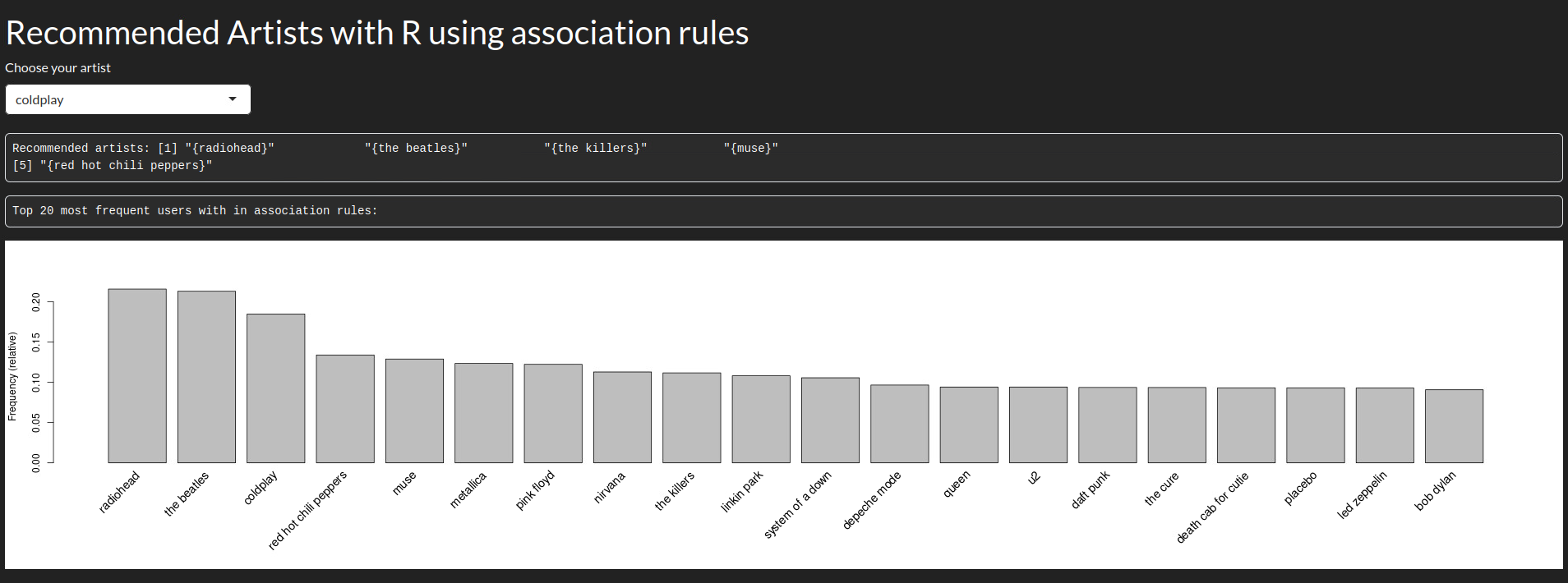
Como he comentado antes, vamos a extraer reglas de asociación usando el algoritmo Apriori; con estas reglas podremos crear un sistema de recomendación de música en base a nuestro dataset, extraído de la plataforma lastfm.
Empezamos importando las librerías con las que vamos a trabajar y el dataset:
library(readr)
library(dplyr)
library(ggplot2)
library(arules)
music_data <- as.data.frame(read_tsv("datasets/lastfm-dataset-360K/usersha1-artmbid-artname-plays.tsv"))Como pequeña anotación: una vez se lee el fichero este es un tibble (explicado en mi publicación de text-mining), ya que me dió problemas al trabajar con el paquete arules a la hora de crear las transacciones.
Cambio el nombre de las columnas para manejar mejor el conjunto de datos:
names(music_data) <- c("user","artist-id","artist","plays")
music_data <- group_by(music_data,user)
music_data <- mutate(music_data,
UserId = cur_group_id()
)
music_data <- ungroup(music_data,user)Además creo una nueva columna que sirve como id del usuario en vez de usar el sha1 del dataset.
Finalmente generamos las reglas de asociación con Apriori, para ello:
Nos quedamos con los datos de interés, para ello dividimos el dataset para quedarnos solo con el id del usuario y los artista que escucha.
Filtramos para obtener los valores únicos, evitando repeticiones.
Transformamos los datos al tipo “transactions”
Generamos las reglas con ciertos valores de confianza y soporte.
Nos quedamos con las mejores reglas en base al parámetro lift
music_by_user <- split(x=music_data[,"artist"],f=music_data$UserId)
music_by_user <- lapply(music_by_user, unique)
transaction_music_by_user <- as(music_by_user,"transactions")
rules <- apriori(transaction_music_by_user,list(support=.01, confidence=.5))
best_rules <- sort(subset(rules,subset=lift > 1),by="confidence")Una vez tenemos las reglas, solo nos queda filtrar la parte izquierda o lhs y encontrar las que tengan al artista en cuestión, devolviendo al usuario la parte derecha o rhs. Para ello despliego una plataforma web que he programado para que el usuario pueda seleccionar al artista, recibiendo las recomendaciones.